MapReduce Tutorial
MapReduce tutorial provides basic and advanced concepts of MapReduce. Our MapReduce tutorial is designed for beginners and professionals.
Our MapReduce tutorial includes all topics of MapReduce such as Data Flow in MapReduce, Map Reduce API, Word Count Example, Character Count Example, etc.
What is MapReduce?
A MapReduce is a data processing tool which is used to process the data parallelly in a distributed form. It was developed in 2004, on the basis of paper titled as “MapReduce: Simplified Data Processing on Large Clusters,” published by Google.
The MapReduce is a paradigm which has two phases, the mapper phase, and the reducer phase. In the Mapper, the input is given in the form of a key-value pair. The output of the Mapper is fed to the reducer as input. The reducer runs only after the Mapper is over. The reducer too takes input in key-value format, and the output of reducer is the final output.
Steps in Map Reduce
- The map takes data in the form of pairs and returns a list of <key, value> pairs. The keys will not be unique in this case.
- Using the output of Map, sort and shuffle are applied by the Hadoop architecture. This sort and shuffle acts on these list of <key, value> pairs and sends out unique keys and a list of values associated with this unique key <key, list(values)>.
- An output of sort and shuffle sent to the reducer phase. The reducer performs a defined function on a list of values for unique keys, and Final output <key, value> will be stored/displayed.
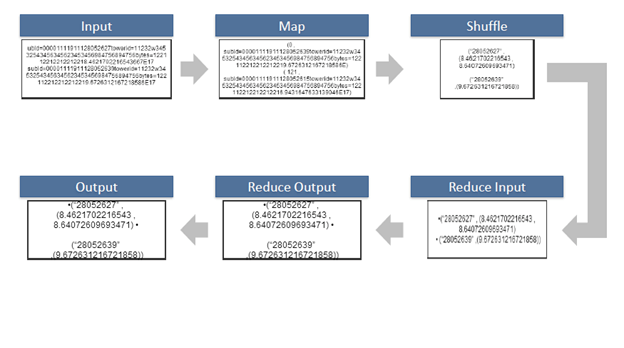
Sort and Shuffle
The sort and shuffle occur on the output of Mapper and before the reducer. When the Mapper task is complete, the results are sorted by key, partitioned if there are multiple reducers, and then written to disk. Using the input from each Mapper <k2,v2>, we collect all the values for each unique key k2. This output from the shuffle phase in the form of <k2, list(v2)> is sent as input to reducer phase.
ADVERTISEMENT
Usage of MapReduce
- It can be used in various application like document clustering, distributed sorting, and web link-graph reversal.
- It can be used for distributed pattern-based searching.
- We can also use MapReduce in machine learning.
- It was used by Google to regenerate Google’s index of the World Wide Web.
- It can be used in multiple computing environments such as multi-cluster, multi-core, and mobile environment.
Prerequisite
Before learning MapReduce, you must have the basic knowledge of Big Data.
Audience
Our MapReduce tutorial is designed to help beginners and professionals.
Problem
We assure that you will not find any problem in this MapReduce tutorial. But if there is any mistake, please post the problem in contact form.