In signal processing, k-means clustering is an essential and widely used clustering algorithm. The algorithm aims to divide a data set into k clusters using examples. Each example is a numerical vector that can compute the Euclidean distance between two vectors.
The primary example below shows how data is partitioned into k = 2 clusters, with the Euclidean distance between samples being shortest to the cluster’s centroid (center), indicating membership.
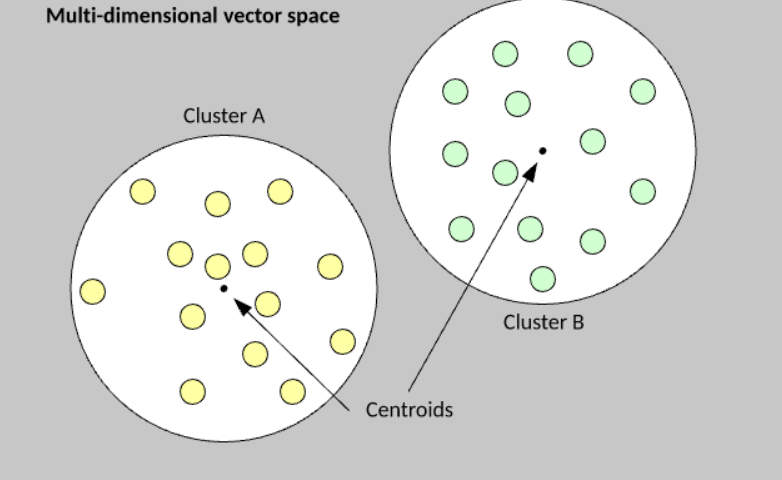
The k-means method is straightforward to comprehend and use.
You start by assigning each example from the data set to a cluster at random, then calculate the cluster’s centroid as the mean of all member examples. Finally, repeat the data set to see if a model is closer to the member cluster or the alternate cluster (assuming k = 2).
The example is relocated to the new cluster, and its centroid is recalculated if the member is closer to the other set. This step is repeated until no more examples are transferred to the alternate cluster.
As shown, k-means divides the sample data set into k clusters without considering the features present in the example vectors.