Lasso and Ridge regression
In Ridge Regression, the OLS loss function is augmented in such a way that we not only minimize the sum of squared residuals but also penalize the size of parameter estimates, in order to shrink them towards zero:
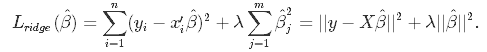
Solving this for
β^ β^ gives the ridge regression estimates
β^ ridge=(X′ X+λI)−1(X′Y)
β^ridge=(X′X+λI)−1(X′Y), where I denote the identity matrix.
The λ parameter is the regularization penalty.
Ridge regression assumes the predictors are standardized and the response is centered
Ridge, LASSO and Elastic net algorithms work on same principle. They all try to penalize the Beta coefficients so that we can get the important variables (all in case of Ridge and few in case of LASSO). They shrink the beta coefficient towards zero for unimportant variables. These techniques are well being used when we have more numbers of predictors/features than observations. The only difference between these 3 techniques are the alpha value. If you look into the formula you can find the important of alpha.

Here lambda is the penalty coefficient and it’s free to take any allowed number while alpha is selected based on the model you want to try .
So if we take alpha = 0, it will become Ridge and alpha = 1 is LASSO and anything between 0–1 is Elastic net.