Machine Comprehension is a very interesting but challenging task in both Natural Language Processing (NLP) and artificial intelligence (AI) research. There are several approaches to natural language processing tasks. With recent breakthroughs in deep learning algorithms, hardware and user-friendly APIs like TensorFlow, some tasks have become feasible up to a certain accuracy. This article contains information about TensorFlow implementations of various deep learning models, with a focus on problems in natural language processing. The purpose of this project article is to help the machine to understand the meaning of sentences, which improves the efficiency of machine translation, and to interact with the computing systems to obtain useful information from it.
Understanding Natural Language Processing:
Our ability to evaluate the relationship between sentences is essential for tackling a variety of natural language challenges, such as text summarization, information extraction, and machine translation. This challenge is formalized as the natural language inference task of Recognizing Textual Entailment (RTE), which involves classifying the relationship between two sentences as one of entailment, contradiction, or neutrality. For instance, the premise “Garfield is a cat”, naturally entails the statement “Garfield has paws”, contradicts the statement “Garfield is a German Shepherd”, and is neutral to the statement “Garfield enjoys sleeping”.
Natural language processing is the ability of a computer program to understand human language as it is spoken. NLP is a component of artificial intelligence which deal with the interactions between computers and human languages in regards to processing and analyzing large amounts of natural language data. Natural language processing can perform several different tasks by processing natural data through different efficient means. These tasks could include:
Answering questions about anything (what Siri*, Alexa*, and Cortana* can do).
Sentiment analysis (determining whether the attitude is positive, negative, or neutral).
Image to text mappings (creating captions using an input image).
Machine translation (translating text to different languages).
Speech recognition
Part of Speech (POS) tagging.
Entity identification
The traditional approach to NLP involved a lot of domain knowledge of linguistics itself.
Deep learning at its most basic level, is all about representation learning. With convolutional neural networks (CNN), the composition of different filters is used to classify objects into categories. Taking a similar approach, this article creates representations of words through large datasets.
Conversational AI: Natural Language Processing Features
Natural Language Processing (NLP)
Text Mining ™
Computational Linguistics (CL)
Machine Learning on Text Data (ML on Text)
Deep Leaning approaches for Text Data (DL on Text)
Natural Language Understanding (NLU)
Natural Language Generation (NLG)
Conversational AI, has seen several amazing advances in recent years, with significant improvements in automatic speech recognition (ASR), text to speech (TTS), and intent recognition, as well as the significant growth of voice assistant devices like the Amazon Echo and Google Home.
Using deep learning techniques can work efficiently on NLP related problems. This article uses back propagation and stochastic gradient descent (SGD)4 algorithms in the NLP models.
Loss depends on each element of the training set, especially when it is compute-intensive, which in the case of NLP problems is true as the data set is large. As gradient descent is iterative, it has to be done through many steps which means going through the data hundreds and thousands of times. Estimate the loss by taking the average loss from a random, small data set chosen from the larger data set. Then compute the derivative for that sample and assumes that the derivative is the right direction to use the gradient descent. It might even increase the loss, not reduce it. Compensate by doing it many times, taking very small steps each time. Each step is cheaper to compute and overall will produce better performance. The SGD algorithm is at the core of the deep learning.
Word Vectors:
Words need to be represented as input to the machine learning models, one mathematical way to do this is to use vectors. There are an estimated 13 million words in English language, but many of these are related.
Search for an N-dimensional vector space (where N << 13 million) that is sufficient to encode all semantics in our language. To do this, there needs to be an understanding of the similarity and difference between words. The concept of vectors and distances between them (Cosine, Euclidean etc.) can be exploited to find similarities and differences between words.

How Do We Represent Meaning of Words?
If separate vectors are used for all of the +13 million words in the English vocabulary, several problems can occur. First, there will be large vectors with a lot of ‘zeroes’ and one ‘one’ (in different position representing a different word). This is also known as one-hot encoding. Second, when searching for phrases such as “hotels in New Jersey” in Google, expectations are that results pertaining to “motel”, “lodging”, “accommodation” in New Jersey are returned. And if using one-hot encoding, these words have no natural notion of similarity. Ideally, dot products (since we are dealing with vectors) of synonym/similar words would be close to one of the expected results.

Word2vec8 is a group of models which helps derive relations between a word and its contextual words. Beginning with a small, random initialization of word vectors, the predictive model learns the vectors by minimizing the loss function. In Word2vec, this happens with a feed-forward neural network and optimization techniques such as the SGD algorithm. There are also count-based models which make a co-occurrence count matrix of words in the corpus; with a large matrix with a row for each of the “words” and columns for the “context”. The number of “contexts” is of course large, since it is essentially combinatorial in size. To overcome the size issue, singular value decomposition can be applied to the matrix, reducing the dimensions of the matrix and retaining maximum information.
Software and Hardware:
The programming language being used is Python 3.5.2 with Intel Optimization for TensorFlow as the framework. For training and computation purposes, the Intel AI DevCloud powered by Intel Xeon Scalable processors were used. Intel AI DevCloud can provide a great performance bump from the host CPU for the right application and use case due to having 50+ cores and its own memory, interconnect, and operating system.
Training Models for NLP: Langmod_nn and Memn2n-master
Langmod_nn Model –
The Langmod_nn model6 builds a three-layer Forward Bigram Model neural network consisting of an embedding layer, a hidden layer, and a final softmax layer where the goal is to use a given word in a corpus to attempt to predict the next word.
To pass the input into one hot encoded vector of dimensions of 5000.
Input:
A word in a corpus. Because the vocabulary size can get very large, we have limited the vocabulary to the top 5000 words in the corpus, and the rest of the words are replaced with the UNK symbol. Each sentence in the corpus is also double-padded with stop symbols.Output:
The following word in the corpus also encoded one-hot in a vector the size of the vocabulary.
Layers –
The model consists of the following three layers:
Embedding Layer: Each word corresponds to a unique embedding vector, a representation of the word in some embedding space. Here, the embedding, all have dimension 50. We find the embedding for a given word by doing a matrix multiply (essentially a table lookup) with an embedding matrix that is trained during regular backpropagation.
Hidden Layer: A fully-connected feed-forward layer with hidden layer size 100, and rectified linear unit (ReLU) activation.
Softmax Layer: A fully-connected feed-forward layer with layer size equal to the vocabulary size, where each element of the output vector (logits) corresponds to the probability of that word in the vocabulary being the next word.
Loss- The normal cross-entropy loss between the logits and the true labels as the model’s cost.
Optimizer –
A normal SGD Optimizer with learning rate .05.

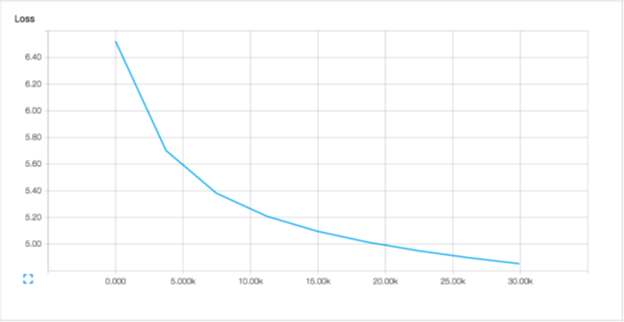
Each epoch (around 480, 000 examples) takes about 10 minutes to train on the CPU. The test log likelihood after epoch five is -846493.44
Memn2n-master :
Memn2n-master7 is a neural network with a recurrent attention model over a possibly large external memory. The architecture is a form of memory network but unlike the model in that work, it is trained end-to-end, and hence requires significantly less supervision during training, making it more generally applicable in realistic settings.
Input data –
This directory includes the first set of 20 tasks for testing text understanding and reasoning in the bAbI5 project. The motive behind these 20 tasks is that each task tests a unique aspect of text and reasoning, and hence by testing the different abilities of the trained models.
For both testing and training, we have 1000 questions each. However, we have not used this much data as it might not be of much use.
The results of this model were a testing accuracy of 99.6%, training accuracy of 97.6%, and validation accuracy of 88%.
TensorFlow framework has shown good results for training neural network models with NLP models showing good accuracy. Training, testing and loss results have been great. Langmod_nn model and memory networks resulted in good accuracy rates with low loss and error value. The flexibility of the memory model allows it to be applied to tasks as diverse as question answering and to language modeling.
Conclusion:
As shown, NLP provides a wide set of techniques and tools which can be applied in all areas of life. By learning the models and using them in everyday interactions, quality of life would highly improve. NLP techniques help to improve communications, reach goals, and improve the outcomes received from every interaction. NLP helps people to use the tools and techniques that are already available to them. By learning NLP techniques properly, people can achieve goals and overcome obstacles.
In the future, NLP will move beyond both statistical and rule-based systems to a natural understanding of language. There are already some improvements made by tech giants. For example, Facebook* tried to use deep learning to understand text without parsing, tags, named-entity recognition (NER) etc., and Google is trying to convert language into mathematical expressions. Endpoint detection using grid long short-term memory networks and end-to-end memory networks on bAbI task performed by Google and Facebook respectively shows the advancement that can be done in NLP models.