Mixture of experts, MoE or ME for short, is an ensemble learning technique that implements the idea of training experts on subtasks of a predictive modeling problem.
In the neural network community, several researchers have examined the decomposition methodology. […] Mixture–of–Experts (ME) methodology that decomposes the input space, such that each expert examines a different part of the space. […] A gating network is responsible for combining the various experts.
— Page 73, Pattern Classification Using Ensemble Methods, 2010.
There are four elements to the approach, they are:
- Division of a task into subtasks.
- Develop an expert for each subtask.
- Use a gating model to decide which expert to use.
- Pool predictions and gating model output to make a prediction.
The figure below, taken from Page 94 of the 2012 book “Ensemble Methods,” provides a helpful overview of the architectural elements of the method.
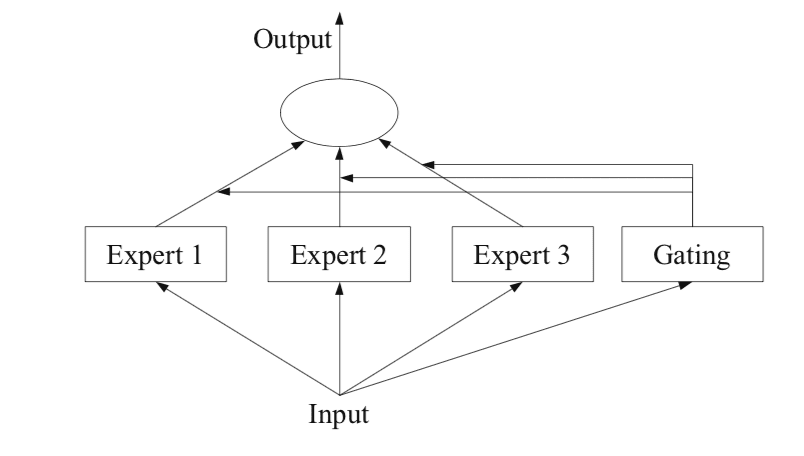
Example of a Mixture of Experts Model with Expert Members and a Gating Network
Taken from: Ensemble Methods
Subtasks
The first step is to divide the predictive modeling problem into subtasks. This often involves using domain knowledge. For example, an image could be divided into separate elements such as background, foreground, objects, colors, lines, and so on.
… ME works in a divide-and-conquer strategy where a complex task is broken up into several simpler and smaller subtasks, and individual learners (called experts) are trained for different subtasks.
— Page 94, Ensemble Methods, 2012.
For those problems where the division of the task into subtasks is not obvious, a simpler and more generic approach could be used. For example, one could imagine an approach that divides the input feature space by groups of columns or separates examples in the feature space based on distance measures, inliers, and outliers for a standard distribution, and much more.
… in ME, a key problem is how to find the natural division of the task and then derive the overall solution from sub-solutions.
— Page 94, Ensemble Methods, 2012.
Expert Models
Next, an expert is designed for each subtask.
The mixture of experts approach was initially developed and explored within the field of artificial neural networks, so traditionally, experts themselves are neural network models used to predict a numerical value in the case of regression or a class label in the case of classification.
It should be clear that we can “plug in” any model for the expert. For example, we can use neural networks to represent both the gating functions and the experts. The result is known as a mixture density network.
— Page 344, Machine Learning: A Probabilistic Perspective, 2012.
Experts each receive the same input pattern (row) and make a prediction.