How will you define the number of clusters in a clustering algorithm?
Though the Clustering Algorithm is not specified, this question is mostly in reference to K-Means clustering where “K” defines the number of clusters. The objective of clustering is to group similar entities in a way that the entities within a group are similar to each other but the groups are different from each other.
For example, the following image shows three different groups.
Within Sum of squares is generally used to explain the homogeneity within a cluster. If you plot WSS for a range of number of clusters, you will get the plot shown below.
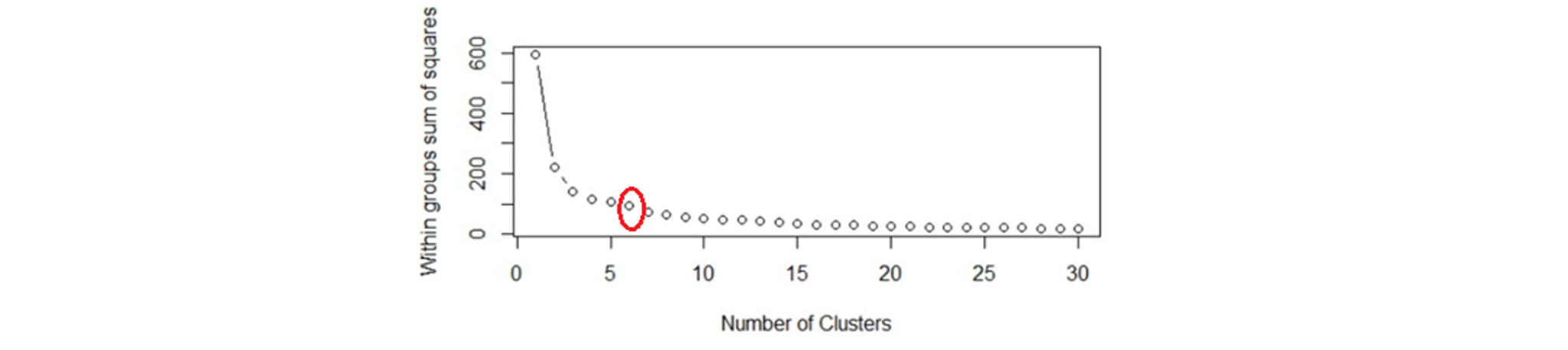
- The Graph is generally known as Elbow Curve.
- Red circled point in above graph i.e. Number of Cluster =6 is the point after which you don’t see any decrement in WSS.
- This point is known as bending point and taken as K in K – Means.
This is the widely used approach but few data scientists also use Hierarchical clustering first to create dendograms and identify the distinct groups from there.
It depends on the clustering algorithm. To give a few examples:
K-means uses the bend in an elbow plot based on the within-cluster sum of squares metric.
Hierarchical Clustering uses dendrograms to determine its clusters.
You can also use a silhouette plot to help to determine if your clusters are sufficient.