Explain cluster sampling technique in Data science
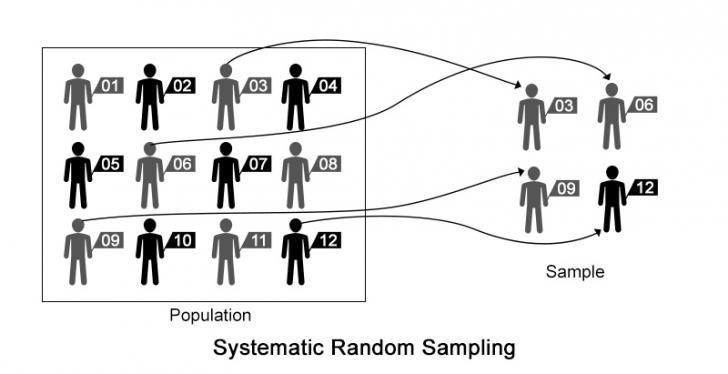
Systematic sampling: Systematic sampling is a type of probability sampling method in which sample members from a larger population are selected according to a random starting point but with a fixed, periodic interval. This interval, called the sampling interval, is calculated by dividing the population size by the desired sample size.
Systematic sampling is to be applied only if the given population is logically homogeneous, because systematic sample units are uniformly distributed over the population. The researcher must ensure that the chosen sampling interval does not hide a pattern. Any pattern would threaten randomness.
Systematic sampling is more convenient than simple random sampling. However, it might also lead to bias if there is an underlying pattern in which we are selecting items from the population.

Sampling Methods
One of the biggest problems we face in data science is dealing with large amount of data on computationally limited machines.
Cluster sampling
Entire population is divided into different clusters and then clusters are randomly selected.
In one stage,entire cluster is selected randomly for sampling.
In second stage,here we first randomly select the clusters,combine those clusters and then randomly select samples from them.
How you do cluster sampling?
- Estimate a population parameter.
- Compute sample variance within each cluster (for two-stage cluster sampling).
- Compute standard error.
- Specify a confidence level.
- Find the critical value (often z-score or a t-score).
- Compute margin of error.
Cluster sampling is less expensive and more quick.
ref:https://medium.com/@rudly.raphael/all-you-need-to-know-about-cluster-sampling-f0dbb5592106