What is Bias?
In the simplest terms, Bias is the difference between the Predicted Value and the Expected Value. To explain further, the model makes certain assumptions when it trains on the data provided. When it is introduced to the testing/validation data, these assumptions may not always be correct.
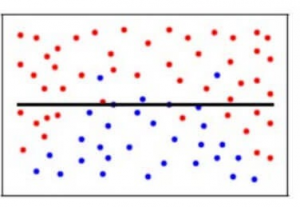
In our model, if we use a large number of nearest neighbors, the model can totally decide that some parameters are not important at all. For example, it can just consider that the Glusoce level and the Blood Pressure decide if the patient has diabetes. This model would make very strong assumptions about the other parameters not affecting the outcome. You can also think of it as a model predicting a simple relationship when the datapoints clearly indicate a more complex relationship:
Mathematically, let the input variables be X and a target variable Y. We map the relationship between the two using a function f.
Therefore,
Y = f(X) + e
Here ‘e’ is the error that is normally distributed. The aim of our model f’(x) is to predict values as close to f(x) as possible. Here, the Bias of the model is:
Bias[f’(X)] = E[f’(X) – f(X)]
As I explained above, when the model makes the generalizations i.e. when there is a high bias error, it results in a very simplistic model that does not consider the variations very well. Since it does not learn the training data very well, it is called Underfitting.
What is a Variance?
Contrary to bias, the Variance is when the model takes into account the fluctuations in the data i.e. the noise as well. So, what happens when our model has a high variance?
The model will still consider the variance as something to learn from. That is, the model learns too much from the training data, so much so, that when confronted with new (testing) data, it is unable to predict accurately based on it.
Mathematically, the variance error in the model is:
Variance[f(x) )=E[X^2]−E[X ]^2
Since in the case of high variance, the model learns too much from the training data, it is called overfitting.
In the context of our data, if we use very few nearest neighbors, it is like saying that if the number of pregnancies is more than 3, the glucose level is more than 78, Diastolic BP is less than 98, Skin thickness is less than 23 mm and so on for every feature…… decide that the patient has diabetes. All the other patients who don’t meet the above criteria are not diabetic. While this may be true for one particular patient in the training set, what if these parameters are the outliers or were even recorded incorrectly? Clearly, such a model could prove to be very costly!
Additionally, this model would have a high variance error because the predictions of the patient being diabetic or not vary greatly with the kind of training data we are providing it. So even changing the Glucose Level to 75 would result in the model predicting that the patient does not have diabetes.
To make it simpler, the model predicts very complex relationships between the outcome and the input features when a quadratic equation would have sufficed. This is how a classification model would look like when there is a high variance error/when there is overfitting :
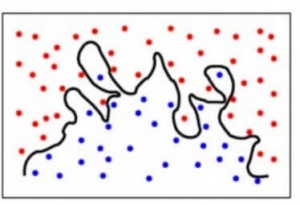
To summarise,
- A model with a high bias error underfits data and makes very simplistic assumptions on it
- A model with a high variance error overfits the data and learns too much from it
- A good model is where both Bias and Variance errors are balanced
Bias-Variance Tradeoff
How do we relate the above concepts to our Knn model from earlier? Let’s find out!
In our model, say, for, k = 1, the point closest to the datapoint in question will be considered. Here, the prediction might be accurate for that particular data point so the bias error will be less.
However, the variance error will be high since only the one nearest point is considered and this doesn’t take into account the other possible points. What scenario do you think this corresponds to? Yes, you are thinking right, this means that our model is overfitting.
On the other hand, for higher values of k, many more points closer to the datapoint in question will be considered. This would result in higher bias error and underfitting since many points closer to the datapoint are considered and thus it can’t learn the specifics from the training set. However, we can account for a lower variance error for the testing set which has unknown values.
To achieve a balance between the Bias error and the Variance error, we need a value of k such that the model neither learns from the noise (overfit on data) nor makes sweeping assumptions on the data(underfit on data). To keep it simpler, a balanced model would look like this:
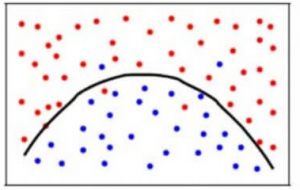
Though some points are classified incorrectly, the model generally fits most of the datapoints accurately. The balance between the Bias error and the Variance error is the Bias-Variance Tradeoff .
The following bulls-eye diagram explains the tradeoff better:
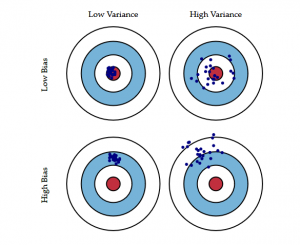
The center i.e. the bull’s eye is the model result we want to achieve that perfectly predicts all the values correctly. As we move away from the bull’s eye, our model starts to make more and more wrong predictions.
A model with low bias and high variance predicts points that are around the center generally, but pretty far away from each other. A model with high bias and low variance is pretty far away from the bull’s eye, but since the variance is low, the predicted points are closer to each other.
In terms of model complexity, we can use the following diagram to decide on the optimal complexity of our model.
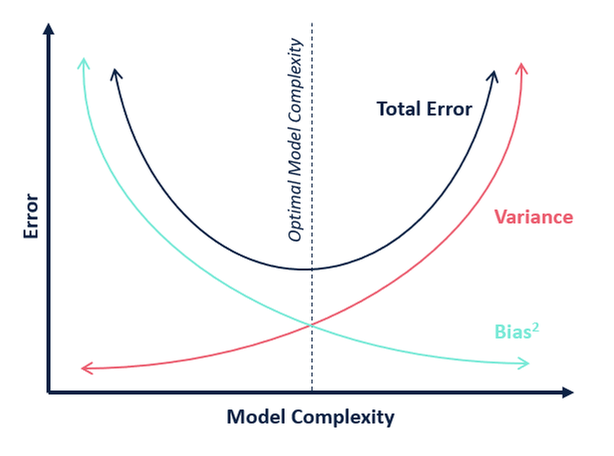
So, what do you think is the optimum value for k?
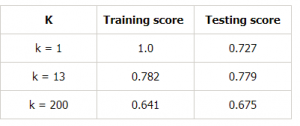
From the above explanation, we can conclude that the k for which
- the testing score is the highest, and
- both the test score and the training score are close to each other
is the optimal value of k. So, even though we are compromising on a lower training score, we still get a high score for our testing data which is more crucial – the test data is after all unknown data.
Let us make a table for different values of k to further prove this:
Conclusion
To summarize, in this article, we learned that an ideal model would be one where both the bias error and the variance error are low. However, we should always aim for a model where the model score for the training data is as close as possible to the model score for the testing data.
That’s where we figured out how to choose a model that is not too complex (High variance and low bias) which would lead to overfitting and nor too simple(High Bias and low variance) which would lead to underfitting.
Bias and Variance plays an important role in deciding which predictive model to use. I hope this article explained the concept well