
 SQL
SQL
 HTML/CSS/JS
HTML/CSS/JS
 Coding
Coding



 Settings
Settings Logout
LogoutK
[su_table]
| ### Word | ### Description |
|---|---|
| K-Means | It is a type of unsupervised algorithm which solves the clustering problem. It is a procedure which follows a simple and easy way to classify a given data set through a certain number of clusters (assume k clusters). Data points inside a cluster are homogeneous and heterogeneous to peer groups. |
 |
|
|Keras|Keras is a simple, high-level neural network library, written in Python. It is capable of running on top of Tensorflow and Theano. This is done to make design and experiments with Neural Networks easier.
Following are some important features of Keras:
- User friendliness
- Modularity
- Easy extensibility
- Work with Python|
|kNN|K nearest neighbors is a simple algorithm that stores all available cases and classifies new cases by a majority vote of its k neighbors. The case being assigned to the class is most common amongst its K nearest neighbors measured by a distance function.
These distance functions can be Euclidean, Manhattan, Minkowski and Hamming distance. First three functions are used for continuous function and fourth one (Hamming) for categorical variables. If K = 1, then the case is simply assigned to the class of its nearest neighbor. At times, choosing the value for K can be a challenge while performing KNN modeling.
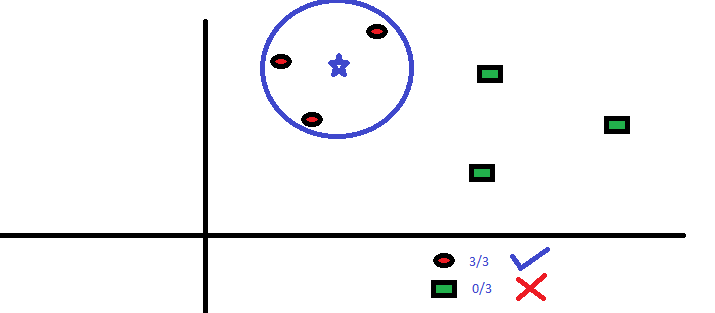
-
Read more here.|
|Kurtosis|Kurtosis is defined as the thickness (or heaviness) of the tails of a given distribution. Depending on the value of kurtosis, it can be classified into the below 3 categories: -
Mesokurtic: The distribution with kurtosis value equal to 3. A random variable which follows a normal distribution has a kurtosis value of 3
-
Platykurtic: If the kurtosis is less than 3. In this, the given distribution has thinner tails and a lower peak than a normal distribution
-
Leptykurtic: When the kurtosis value is greater than 3. In this, the given distribution has fatter tails and a higher peak than a normal distribution
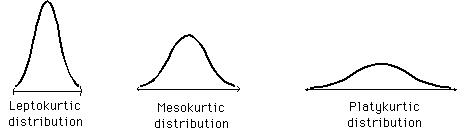 |
|